もくじ
COVID-19Hokkaidoデータ編①スクレイピングなどによる初期データ作成←この記事だよ! COVID-19Hokkaidoデータ編②オープンデータ化+自動更新 COVID-19Hokkaidoデータ編③完全自動化
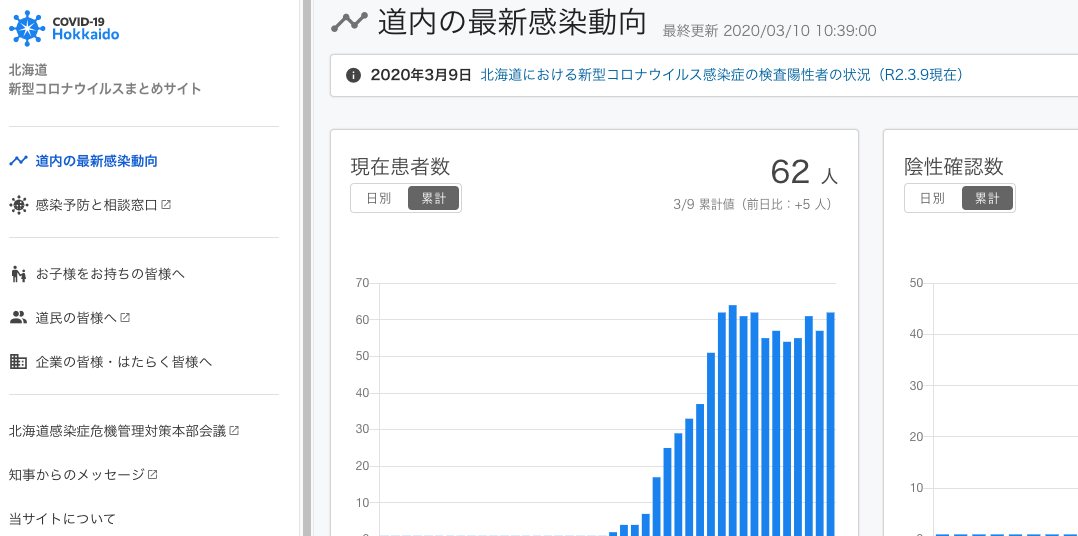
はじめに
東京都とCode for Japanにより東京都公式コロナウイルス対策サイトがリリースされ、そのソースコードがなんとGitHubでMITライセンスで公開されました。つまり他の道府県でも「同様のデータを用意できれば」同じように可視化するウェブアプリケーションを作成出来るという事です(実際はサーバーのリソースなども必要になってきますが)。画期的な取組です。
さてそんな訳で、全国各地の動きも活発化し、北海道ではCode for Sapporoや道内IT企業、自治体職員など多彩なバックグラウンドをもつ有志によるJUST道ITというグループが結成され、3月6日に東京都からフォークしたプロジェクトが3月9日の昼にリリースされました。
Covid19Hokkaido 北海道新型コロナウイルスまとめサイト
ほぼ同時に神奈川でも同様の形でサイトがリリースされたり、これらの動きが窓の杜さんやITmediaさんにも紹介されるなど、東京発の画期的な取組が全国へ波及し始めています。
この記事について
前述のとおり、「同様のデータを用意できれば」同じように可視化するウェブアプリケーションを作成出来る訳ですが、自治体によってデータの公開状況・提供方法が異なるため、それらをうまいこと収集してデータをこさえるのが重要になってくる訳です。私も微力ながら本プロジェクトに参加させて頂き、データ周りの開発に携わった事から、データの取得・生成・管理のフローについて本記事にまとめる事とします。
東京都公式サイトのデータ
東京都公式サイト(以下都サイト)のソースコードでは、data/data.jsonというファイルに可視化されるべきデータが全て格納されており、key別に以下の構成になっていました(フォーク時点)。
| key | 東京都サイトでの名称 | 内容 |
|---|---|---|
| contacts | 新型コロナコールセンター相談件数 | 日別コールセンター相談件数 |
| discharges | 未実装 | 退院者別属性 |
| discharges_summary | 未実装 | 日別退院者数 |
| inspections | 未実装 | 日別検査データ |
| inspections_summary | 未実装(devでは検査実施日別状況) | 検査により陽性が判明した日・人数のデータ(1/24〜、都内外別) |
| patients | 陽性患者の属性 | 感染者別属性 |
| patients_summary | 陽性患者数 | 日別感染者数 |
| better_patients_summary | 未実装 | 感染者数、退院者数、死亡者数、軽症、中等症、重症の日別データ |
| querents | 帰国者・接触者電話相談センター相談件数 | 日別電話相談センター相談件数 |
またkeyごとの各カラムの意味は以下のとおりです(必要なデータのみ)。
| key | colum | 東京版の何に使われているか | memo |
|---|---|---|---|
| contacts | 日付 | 新型コロナコールセンター相談件数 | utils/formatGraph.tsに読まれます |
| contacts | 小計 | 新型コロナコールセンター相談件数 | utils/formatGraph.tsに読まれます |
| inspections_summary | labels | 検査実施日別状況 | index.vueで読まれます |
| inspections_summary | 都内 | 検査実施日別状況 | index.vueで読まれます |
| inspections_summary | その他 | 検査実施日別状況 | index.vueで読まれます |
| patients | リリース日 | 陽性患者の属性 | utils/formatTable.tsに読まれます |
| patients | 居住地 | 陽性患者の属性 | utils/formatTable.tsに読まれます |
| patients | 年代 | 陽性患者の属性 | utils/formatTable.tsに読まれます |
| patients | 性別 | 陽性患者の属性 | utils/formatTable.tsに読まれます |
| patients_summary | 日付 | 陽性患者数 | utils/formatGraph.tsに読まれます |
| patients_summary | 小計 | 陽性患者数 | utils/formatGraph.tsに読まれます |
| querents | 日付 | 帰国者・接触者電話相談センター相談件数 | utils/formatGraph.tsに読まれます |
| querents | 小計 | 帰国者・接触者電話相談センター相談件数 | utils/formatGraph.tsに読まれます |
以上を踏まえたdata.jsonの構造は以下です。
{
"contacts": {
"data": [
{
"日付": "2020-02-14T08:00:00.000Z",
"曜日": "金",
"9-13時": "",
"13-17時": "",
"17-21時": "",
"date": "2020-02-14",
"w": "",
"short_date": "02/14",
"小計": 172
},
{
"日付": "2020-02-15T08:00:00.000Z",
"曜日": "土",
"9-13時": "",
"13-17時": "",
"17-21時": "",
"date": "2020-02-15",
"w": "",
"short_date": "02/15",
"小計": 179
},
//以下略
],
"date": "2020-03-07T17:55:16.974293+09:00"
},
"querents": {},
"patients": {},
"patients_summary": {},
"discharges": {},
"discharges_summary": {},
"inspections": {},
"inspections_summary": {},
"better_patients_summary": {},
"last_update": "2020-03-07T17:55:16.974293+09:00", //ISO-8601フォーマットのdatetime
"main_summary": {}
}
//last_updateとmain_summary以外は、contactsと同様にdateとdataを持ちます
//contacts以外は要素を割愛しています
//main_summaryは特殊ですが、システム上は使用されていないので無視しても問題ありません
北海道版V0のデータ
V0時点で外部から取得可能なデータは北海道のウェブサイトに掲載されているデータに限られており、その中で機械判読可能な情報は、HTMLのtableに表示される患者の属性のみでした。また、札幌市が相談件数のCSVファイルをオープンデータとして公開していた事から、北海道版V0時点ではこれらのデータを用いる事となります。使えるデータと形式は以下のとおりです。
| key | データの出所 | 形式 |
|---|---|---|
| patients | 道ウェブサイト | HTMLのテーブル |
| patients_summary | 道ウェブサイト | HTMLのテーブル |
| contacts | 札幌市 | CSVファイル |
| querents | 札幌市 | CSVファイル |
※検査データはV0では用意出来ないと判断し、表示しない事としました
以上から、V0時点とV1以降の稼働イメージが以下のとおりになりました。
 以下、データの取得・生成・管理のフローをまとめます。
以下、データの取得・生成・管理のフローをまとめます。
データの取得・生成
さすがに手作業でデータを更新する事はなく、データ取得・生成を自動で行うスクリプトを書きました。 Kanahiro/covid19hokkaido_scraping ※上記はV0リリース時の状態のURLです(履歴から復元) ※現在はcodeforsapporoにフォークされそちらが本流になっております
本スクリプト(main.py)は実行されると以下の手順でdata.jsonを生成します(V0時点)。
- data.jsonに準拠した構造のdictを生成(各要素のデータは空)
- 道ウェブサイトをスクレイピングしてdictに変換
- importの中にあるcsvファイルをすべてdictに変換
- 2,3のdictを1の各要素に突っ込む
- 1をdata.jsonとして出力
道ウェブサイトのスクレイピング
道ウェブサイトは、PythonとBeautifulSoupによりスクレイピングしています。table内の全ての行(tr)を取得してdictに変換しています。 ※コードは割愛、上記リポジトリのpatients.pyになります
CSVファイルの読み込み
V0時点で、contantsとquerentsはソースが生のCSVファイルであるため、importディレクトリ内に保存されたCSVファイルを全て読み込みdictに変換する仕組みとしました。
データの管理
V0から現在まで、本スクリプトで生成されたdata.jsonを「手動で」本体リポジトリにプッシュしています。 data.jsonの生成自体はGitHub Actionsでスケジューリングしており、15分間隔でmain.pyを実行する事で生成・別ブランチにプッシュするようになっています。 なので、リリース時点では適宜私がdata.jsonを本体にプッシュしていました(1日2,3回くらい)。
自動化へ向けて
V0段階ではdata.jsonのプッシュが手動になっており、手間や即時性を考えると自動化したい訳です。 APIサーバーを別途立てるなど、様々な手法が考えられますが、以下であればGitHubのみで完結します。 (都公式も、他自治体での運用も考えてGitHubだけで完結するように作っていたのかなぁ)
- data.jsonの生成をGitHub Actionsで自動化
- その自動生成されたjsonファイルに直接アクセス・非同期通信し、UIに反映させる
※都公式サイトのUIは(フォーク時点では)非同期通信は想定されていなかったので、適宜フロントの修正が必要です