もくじ
COVID-19Hokkaidoデータ編①スクレイピングなどによる初期データ作成 COVID-19Hokkaidoデータ編②オープンデータ化+自動更新へ向けて COVID-19Hokkaidoデータ編③完全自動化←この記事だよ!
完全自動化へ向けて
現状
- GitHub Actionsにより、元データの読み込み・jsonファイルの生成は既に自動化されている
- GitHub Pagesにより、自動で生成されたjsonファイルのホスティングは実装されている
課題
- 元データはオープンデータとなったものの、ファイルは各自治体担当者さんの手作業で作成されるため、入力値のバリデーションが必要
- データの不整合などでjsonファイルの生成を失敗した場合、何らかのアラートが必要
バリデーション
Python内部でdictを生成し、json.dump()でjsonファイルに書き出しています。つまりdictのデータをバリデーションすべきと言えます。 では何をバリデーションすべきか。たとえばフロントで参照したkeyが存在しなかったら困ります、なのでkeyチェックが必要です。また、日付keyに何故か整数値が入っていたらこれまた困ります。なのでkeyごとに型チェックが必要です。
これら2点はフルスクラッチで実装しても良さそうですが、先人が発明した車輪を使わせてもらう事とします。「jsonschema」を利用します。
参考サイト:https://medium.com/veltra-engineering/python-json-schema-validation-6936238f107d
jsonschemaのインストール
pip install jsonschema
jsonschemaでバリデーション
事前に定義しておいた、JSONの構造・型に、与えられたdictが適合するかチェックします。 適合しなければエラーが出て、適合すれば何も出力されません。
使い方などは上記参考サイトで丁寧に解説されていますので、実装のみ紹介します。
SCHEMAS = {
"patients":{ スキーマ定義 },
"contacts":{ スキーマ定義 }
#〜割愛〜
}
というように、keyごとにスキーマ定義をSCHEMASとして定義します。
def validate(self):
for key in self.data:
jsonschema.validate(self.data[key], SCHEMAS[key])
self.dataとSCHEMASはkeyが一致しています。self.data[key]は、そのままjsonに出力すべきdictです。 したがって、例えば入力ミスなどでkeyが欠損していたり、型が整合しない場合はエラーが発生して処理が中断します(jsonは生成されない)。 おかしなjsonは生成されず、最後に正常に出力されたjsonが残り続ける訳です。 (5と入力すべき箇所に五と入力されていれば引っかかりますが、6と入力されていたら素通りします。この手のヒューマンエラーはそもそも避けようがない気もしますが)
たとえばdateにはintegerが入るべき、と定義したにも関わらずデータがstringだった場合は、以下のようなエラーが出て処理が中断されます。
Traceback (most recent call last):
File "main.py", line 231, in <module>
dm.validate()
File "main.py", line 90, in validate
jsonschema.validate(self.data[key], SCHEMAS[key])
File "/opt/hostedtoolcache/Python/3.8.2/x64/lib/python3.8/site-packages/jsonschema/validators.py", line 934, in validate
raise error
jsonschema.exceptions.ValidationError: '2020-03-17T21:31:40.309090+09:00' is not of type 'integer'
Failed validating 'type' in schema['properties']['last_update']:
{'default': '', 'type': 'integer'}
On instance['last_update']:
'2020-03-17T21:31:40.309090+09:00'
##[error]Process completed with exit code 1.
Slackにエラーをアラート
参考サイト: Qiita - SlackのWebhook URL取得手順 Qiita - GitHub Actionsを定期実行して結果をSlackに通知する
理由問わず、データ生成に失敗した場合にSlackに通知するようにします。 上記サイトを参考に以下のとおりyamlを記述しました。
name: Python application
on:
schedule:
- cron: '0 * * * *'
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python 3.8
uses: actions/setup-python@v1
with:
python-version: 3.8
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run script
run: |
python main.py
- name: Slack Notification
# ここから
if: failure()
uses: rtCamp/action-slack-notify@master
env:
SLACK_MESSAGE: 'Error occurred! Please check a log!'
SLACK_TITLE: ':fire: Data Update Error :fire:'
SLACK_USERNAME: covid19hokkaido_scraping
SLACK_WEBHOOK: ${{ secrets.SLACK_WEBHOOK }}
# ここまで追加
- name: deploy
uses: peaceiris/actions-gh-pages@v3
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: ./data
publish_branch: gh-pages
Setting→SecretsにSLACK_WEBHOOKを追加しておく必要があります(さもなくばwebhookURLがオープンソースになってしまいます)。
Secretsに格納した値は暗号化されます。yamlからはsecrets.{ なまえ }で取得出来ます。 GITHUBから始まる{ なまえ }は使えません。
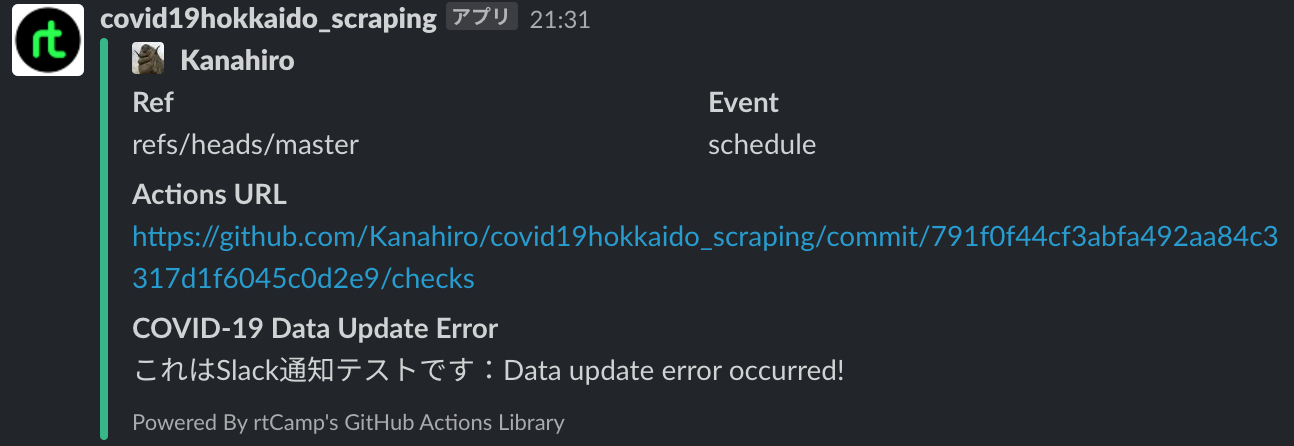
以上を実装すると、エラー発生時には以下のようにSlackに投稿されます。
終わりに
以上で、データ取得→jsonファイル生成のバリデーション込みの自動化処理が完成しました。 ただ、現在はkeyチェックと型チェックのみなので、例えばあまりにもな異常値を検知する仕組みなど、バリデーションにはキリがありません。 またデータ生成は自動化されましたが、フロント側の非同期通信はデバッグ含めた実装中です。 今後も改善の余地がありますが、当初の半分手作業から比べると劇的に運用がラクになったと思います。以上で3回に渡った連載は終了となります、ありがとうございました。