QGIS プラグイン「GTFS-GO」
https://github.com/MIERUNE/GTFS-GO
昨年、GTFS データを解析して QGIS 上に可視化するプラグインGTFS-GOを公開しました(紹介記事)。多くの方に使われ、広く反響をいただいたところです。その後、公共交通データの整備や分析を手がける(株)トラフィックブレイン社と意見交換する機会がありました。そのなかで、現在(一財)トヨタ・モビリティ基金のバックアップのもと兵庫県豊岡市で進んでいる豊岡スマートコミュニティ推進機構の取組の一環として、本プラグインをより便利な公共交通分析ツールとする機能拡張のご提案があり、快諾しました。結果、両社からサポートを頂きながら開発を進め、新バージョンの公開まで至っております。オープンソースへの多大なるご理解・ご協力に感謝します。
本記事ではGTFS-GOの新バージョンの機能や技術情報を述べます、「そもそも GTFS とは?」などの疑問は前回記事を確認してください。
もくじ
新バージョンの追加機能紹介
公式リポジトリに登録済みなので、QGIS内でインストールすることができます。 https://plugins.qgis.org/plugins/GTFS-GO-master/
- 「より便利な公共交通分析ツールとする機能拡張」とは、
運行頻度図作成機能の追加です。GTFS には時刻表データも含まれており、それを解析することで、運行頻度を停留所間の経路単位で集計する事ができます - また「類似する停留所でまとめて集計したい」というニーズを解決するため、
停留所の名寄せ機能を実装しています - 処理の最適化によって routes と stops の読み込みが高速化
- 多言語対応の強化(後述)
多言語対応
QGIS は世界中に多くのユーザーがおり、GTFS データはグローバルな規格です。なのでユーザーインターフェースは英語を基本とし日本語(とフランス語一部)への翻訳に対応しつつ、日本だけではなくアメリカなどの GTFS データもプリセットしてあります(ニューヨークの地下鉄データなど)。
また、未整備だった README を英語で充実させ、世界中のユーザーが使用できる状態になっています。
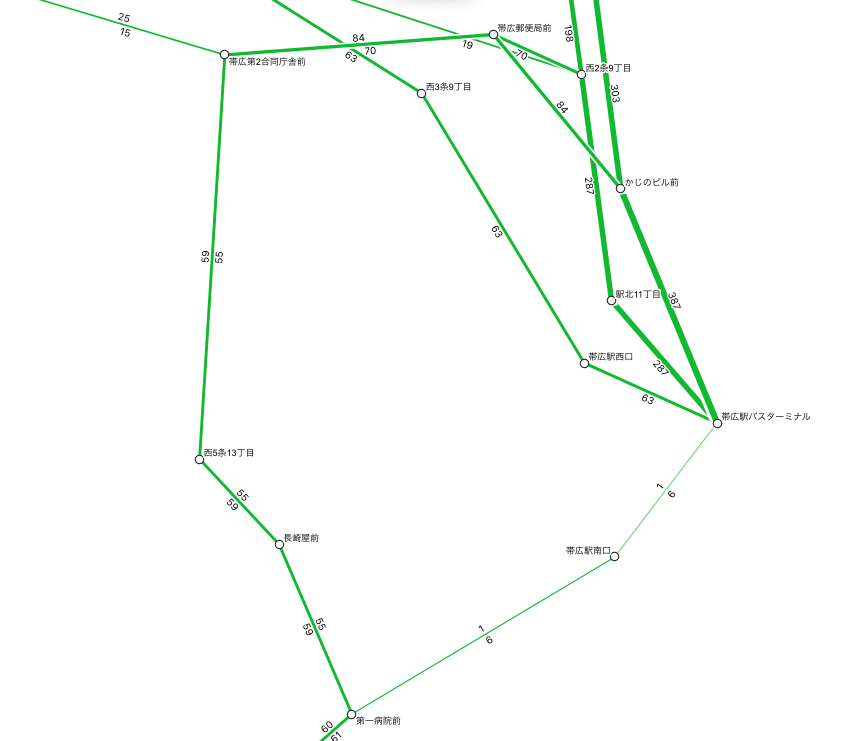
運行頻度図とは
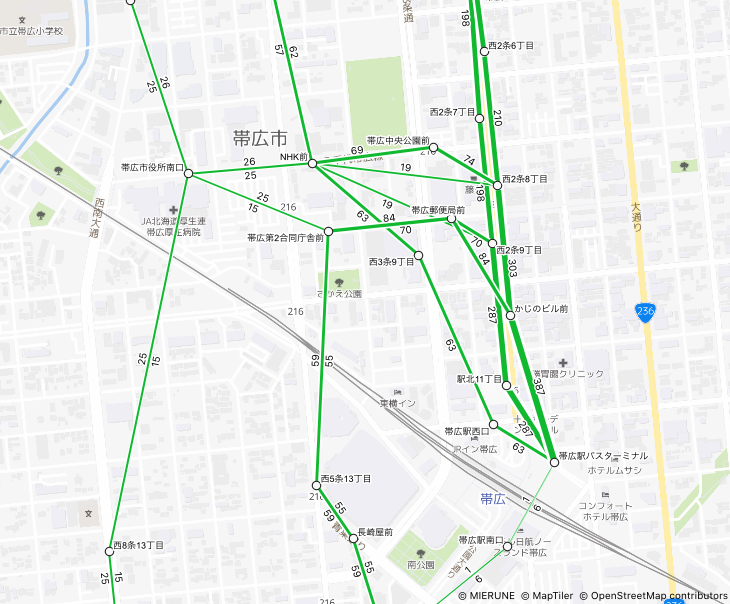
- 2 停留所間の運行頻度を、2 点を繋いだ線分の太さおよび付記される数値によって表現した図
- エリアごとの公共交通の運行頻度が一目でわかる
- 運行頻度の数値は、線分の進行方向に対して左側に表示されます(車道の方向と一致)
- 運行頻度から線分の太さへの換算はGTFS からバスの運行頻度図を作成するを参考にしています
- エリアごとの公共交通の運行頻度が一目でわかる
GTFS-GO で頻度図をつくる
インストールなどは前回記事を参照してください。
使い方
前バージョンから、運行頻度を集計モードが追加されています。
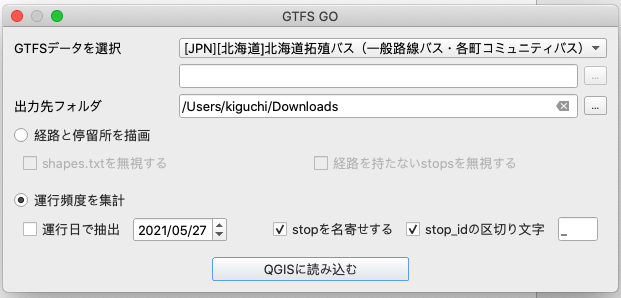
- 運行日で抽出
- 頻度を集計したい日付を指定、読み込む GTFS が対応している日時にしてください
- stop を名寄せする
- 類似する停留所を名寄せし代表停留所とした上で頻度集計を行います
- stop_id の区切り文字
- 名寄せ時のみ有効、stop_id に区切り文字があり、それを目印に名寄せする場合に指定します
※名寄せルールについては後述
「QGIS に読み込む」ボタンを押下すると処理が始まります(データサイズによって数十秒かかる事があります)。
出力データ
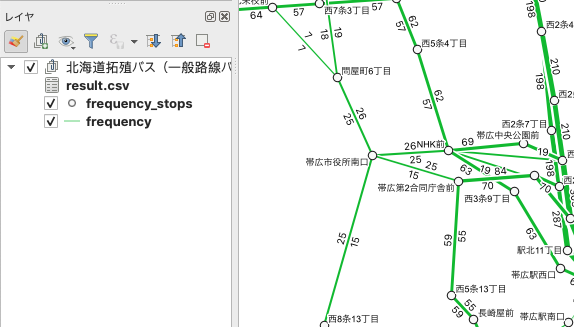
運行頻度を集計モードでは、以下の 3 つのファイルが出力され、QGIS 上でスタイリングされた状態で表示されます。
- result.csv
- 停留所名寄せの新旧対照表
- frequency.geojson
- 停留所間単位の経路データ
- その経路の始点終点の停留所情報などを含む
- frequency_stops.geojson
- 名寄せ後の代表停留所データ
名寄せルール
以下の 3 つのルールを、1 番から優先して適用していき、停留所を名寄せし、代表停留所を生成します。
- 親停留所
- 停留所に親が設定されている場合は親停留所を代表停留所とする
- GTFS は規格上、停留所に親子関係を設定できる
- 代表停留所の ID は親停留所のものを用いる
- 停留所に親が設定されている場合は親停留所を代表停留所とする
- stop_id の接頭辞
- 「stop_id の区切り文字」が設定されている場合、stop_id をその文字で区切り、前方部分が一致する全停留所の重心に代表停留所を設ける
- 例:2 つの stopid が「1234_A」「1234_B」で区切り文字が「」なら、いずれも前方部分が「1234」となり名寄せされる
- 代表停留所の ID は、上記条件に合致した全停留所の ID を昇順にならべ、最も若いものを用いる
- 「stop_id の区切り文字」が設定されている場合、stop_id をその文字で区切り、前方部分が一致する全停留所の重心に代表停留所を設ける
- stop_name が一致かつ近傍
- stop_name が完全に一致し、一定以上近傍にある全停留所の重心に代表停留所を設ける
- 一定以上近傍= 10 進法経緯度の値同士のユークリッド距離が 0.01 未満である事
- このしきい値が実際に示す領域の広さは緯度によって異なるが、実用上無視している
- 代表停留所の ID は、上記条件に合致した全停留所の ID を昇順にならべ、最も若いものを用いる
- stop_name が完全に一致し、一定以上近傍にある全停留所の重心に代表停留所を設ける
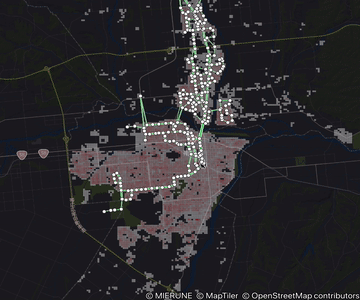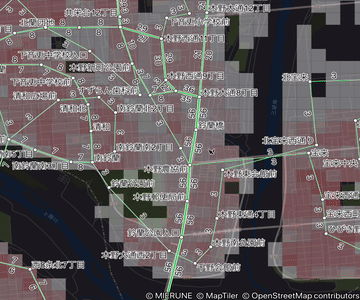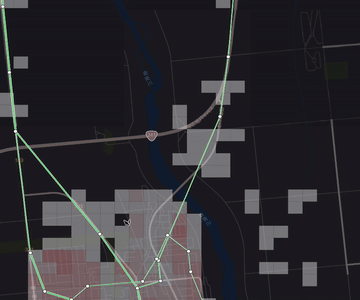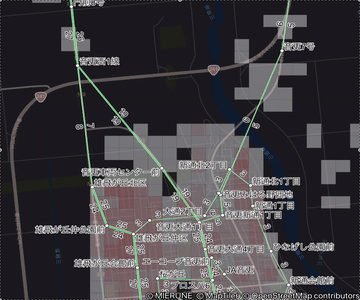
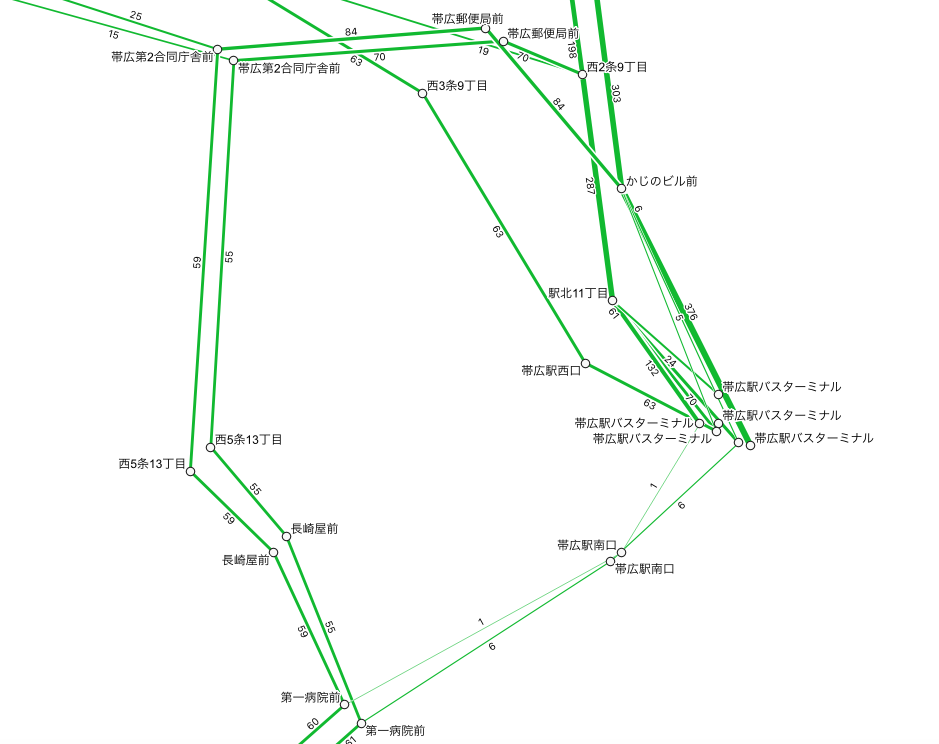
名寄せ例
下記 2 画像は、上記ルールでの名寄せ前後です。
ご覧のとおり、名寄せされている方が、運行頻度がわかりやすくなります。
終わりに
地域の交通サービスの充実度を一目できる運行頻度図は、自治体等による公共交通計画の立案に役立つ一方、その図を作るのが容易ではありませんでした。しかし今後は本プラグインによりGTFSデータが整備されていれば簡単に頻度図が得られます。
さらにバスの乗降人数等のデータを組み合わせることで、地域交通の利用実態を可視化することもできます。(豊岡市における参考例)
GTFS データの活用方法を地図検索サービス以外にも広げることで、GTFS データの価値向上、さらには GTFS データの整備促進にもつながれば幸いです。
技術情報
以下はより具体的な実装のポイントの説明です。
全般
- GTFS テーブル周りの処理はすべて Pandas を用いています
- GTFS を解析するモジュールはプラグイン内で gtfs_parser フォルダに独立しているので、流用可能です(MIT ライセンス)
停留所の名寄せ
- 名寄せルールに基づき、以下の関数では、各 stop_id に対し、名寄せ後の「stop_id、stop_name、座標」を求めています
- これを全 stop_id に対し実行しておきます
def get_similar_stop_tuple(self, stop_id: str, delimiter='', max_distance_degree=0.01):
stops_df = self.dataframes['stops'].sort_values('stop_id')
stop = stops_df[stops_df['stop_id'] == stop_id].iloc[0]
if stop['is_parent'] == 1:
return stop['stop_id'], stop['stop_name'], [stop['stop_lon'], stop['stop_lat']]
if str(stop['parent_station']) != 'nan':
similar_stop_id = stop['parent_station']
similar_stop = stops_df[stops_df['stop_id'] == similar_stop_id]
similar_stop_name = similar_stop[['stop_name']].iloc[0]
similar_stop_centroid = similar_stop[['stop_lon', 'stop_lat']].iloc[0].values.tolist()
return similar_stop_id, similar_stop_name, similar_stop_centroid
if delimiter:
stops_df_id_delimited = self.get_stops_id_delimited(delimiter)
stop_id_prefix = stop_id.rsplit(delimiter, 1)[0]
if stop_id_prefix != stop_id:
similar_stop_id = stop_id_prefix
seperated_only_stops = stops_df_id_delimited[stops_df_id_delimited['delimited']]
similar_stops = seperated_only_stops[seperated_only_stops['stop_id_prefix'] == stop_id_prefix][['stop_name', 'similar_stops_centroid_lon', 'similar_stops_centroid_lat']]
similar_stop_name = similar_stops[['stop_name']].iloc[0]
similar_stop_centroid = similar_stops[['similar_stops_centroid_lon', 'similar_stops_centroid_lat']].values.tolist()[0]
return similar_stop_id, similar_stop_name, similar_stop_centroid
else:
# when cannot seperate stop_id, grouping by name and distance
stops_df = stops_df_id_delimited[~stops_df_id_delimited['delimited']]
# grouping by name and distance
similar_stops = stops_df[stops_df['stop_name'] == stop['stop_name']][['stop_id', 'stop_name', 'stop_lon', 'stop_lat']]
similar_stops = similar_stops.query(f'(stop_lon - {stop["stop_lon"]}) ** 2 + (stop_lat - {stop["stop_lat"]}) ** 2 < {max_distance_degree ** 2}')
similar_stop_centroid = similar_stops[['stop_lon', 'stop_lat']].mean().values.tolist()
similar_stop_id = similar_stops['stop_id'].iloc[0]
similar_stop_name = stop['stop_name']
return similar_stop_id, similar_stop_name, similar_stop_centroid
- 上記の処理だけだと同じ代表停留所に名寄せされた停留所が複数個存在することになるので、重複を除去
- 名寄せ後 ID +経緯度文字列が一致していると重複と判定する
self.dataframes['stops']['position_id'] = self.dataframes['stops']['similar_stops_centroid'].map(latlon_to_str)
self.dataframes['stops']['unique_id'] = self.dataframes['stops']['similar_stop_id'] + self.dataframes['stops']['position_id']
self.similar_stops_df = self.dataframes['stops'].drop_duplicates(subset='unique_id')[['position_id', 'similar_stop_id', 'similar_stop_name', 'similar_stops_centroid']].copy()
頻度の集計
stopstop_times テーブルに、stops テーブルを JOIN 済みだとします。
# ソート
stop_times_df = self.dataframes.get('stop_times')[['stop_id', 'trip_id', 'stop_sequence']].sort_values(['trip_id', 'stop_sequence']).copy()
テーブルがソート済みである事を利用して、1 行に前後の停留所情報を押し込みます。
# 1行下からstop_idなどを持ってくる(nextとする)
stop_times_df['prev_stop_id'] = stop_times_df['similar_stop_id']
stop_times_df['prev_trip_id'] = stop_times_df['trip_id']
stop_times_df['prev_stop_name'] = stop_times_df['similar_stop_name']
stop_times_df['prev_similar_stops_centroid'] = stop_times_df['similar_stops_centroid']
stop_times_df['next_stop_id'] = stop_times_df['similar_stop_id'].shift(-1)
stop_times_df['next_trip_id'] = stop_times_df['trip_id'].shift(-1)
stop_times_df['next_stop_name'] = stop_times_df['similar_stop_name'].shift(-1)
stop_times_df['next_similar_stops_centroid'] = stop_times_df['similar_stops_centroid'].shift(-1)
# tripの切れ目の行は削除
stop_times_df = stop_times_df.drop(index=stop_times_df.query('prev_trip_id != next_trip_id').index)
1 行に前後の停留所情報があるので、それらを用いて経路に ID を振ります。経路は方向が区別されるので、2 停留所間に往路それぞれの経路が存在します。
# path_id: 前停留所ID + 後停留所ID + 前停留所経緯度文字列 + 後停留所経緯度文字列
stop_times_df['path_id'] = stop_times_df['prev_stop_id'] + stop_times_df['next_stop_id'] + stop_times_df['prev_similar_stops_centroid'].map(latlon_to_str) + stop_times_df['next_similar_stops_centroid'].map(latlon_to_str)
あとは経路 ID をカウントすれば、その集計値が経路ごとの運行頻度になります。